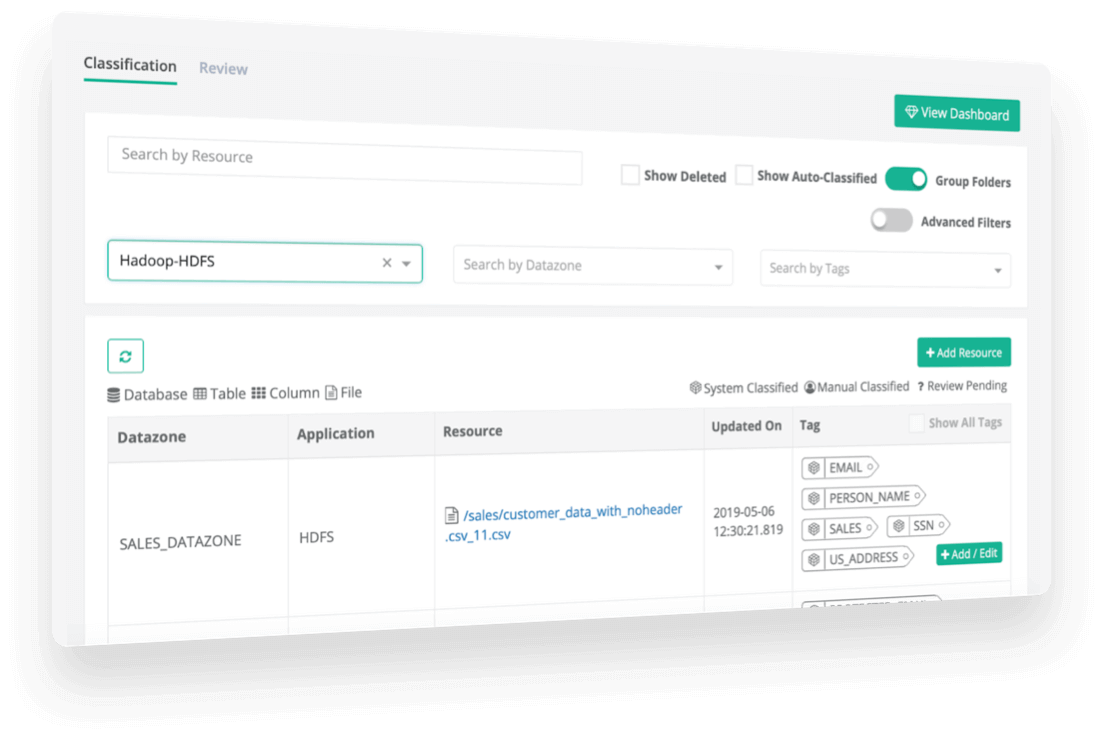
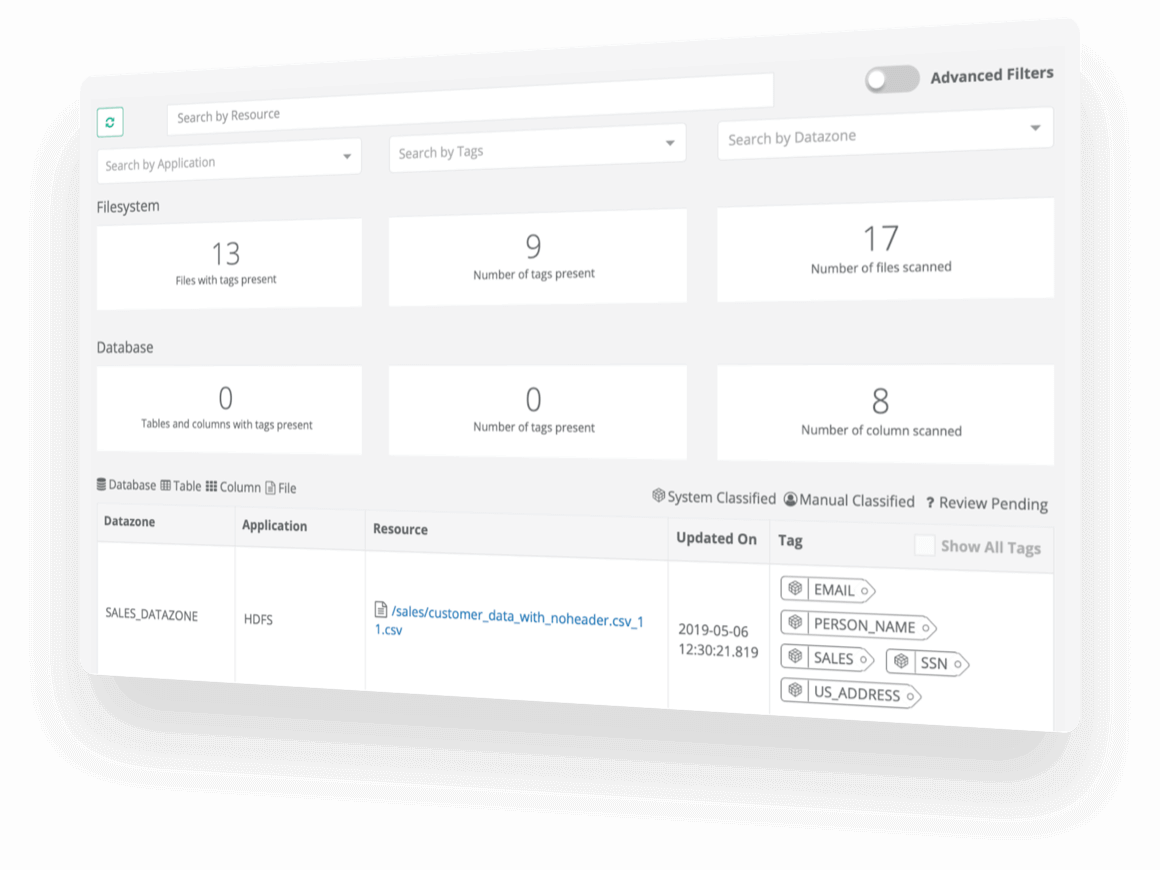
Privacera Solution – Free Trial Agreement
CUSTOMER IS RESPONSIBLE FOR CAREFULLY READING THE TERMS OF THIS TRIAL AGREEMENT BEFORE CLICKING “SUBMIT” OR “ACCEPT” AND/OR ACCESSING OR USING ANY PRIVACERA SOLUTION. BY CLICKING “SUBMIT” OR “ACCEPT” AND/OR ACCESSING OR USING SUCH SERVICES, CUSTOMER CONFIRMS THAT CUSTOMER HAS READ AND ACCEPTS THIS AGREEMENT.
1. License Grant/Limitations/Restrictions
This Trial Agreement (“Agreement”) is made and entered into on the first day that the Trial Services are activated for Customer’s use (“Trial Service Activation Date”), and will remain in effect for the duration of the Trial Period as specified below. The individual who has registered and signed up for the Trial Services represents and warrants that he or she has the legal power and authority to enter into this Agreement and to legally bind the Customer (“Customer”) to the terms of this Trial Agreement. The terms and conditions of this Agreement shall govern the Trial Services to be provided by Privacera during the Trial Period. The term “Privacera” shall include Privacera, and any third parties which are providing third party services or products, on behalf of Privacera, as part of the Trial Services. A Definitions section is included at the end of this Agreement which includes further applicable definitions used in this Agreement.
Subject to the terms and conditions of this Agreement, Privacera hereby grants Customer a non-exclusive, non-transferable, non-assignable, limited license to use the Trial Services during the Trial Period solely for Customer’s own business purposes and strictly for purposes of its own internal evaluation of the PRIVACERA SOLUTION and not for any commercial or competitive purpose. The Trial Service license is limited to a single limited production tenant of Customer. All rights not expressly granted to Customer are reserved by Privacera and its licensors. Privacera reserves the right to make changes, modifications, reduction in functionality and enhancements to the Trial Services, at any time, and from time to time without prior notice.
2. Limitations on Use
Customer may not release to any third party the results of any evaluation of the Trial Services performed by or on behalf of Customer for purposes of monitoring its availability, performance or functionality, or for any other benchmarking or competitive purposes without the prior written approval of Privacera. Customer shall not (i) license, sublicense, sell, resell, transfer, assign, distribute or otherwise commercially exploit or make available to any third party the Trial Services or the Content in any way; (ii) modify or make derivative works based upon the Trial Services or the Content; (iii) reverse engineer the Trial Services; or (iv) access the Trial Services in order to build a competitive product or service. Additionally, Customer shall not use the Trial Services to: (i) send spam or otherwise duplicative or unsolicited messages in violation of applicable laws; (ii) send or store infringing, obscene, threatening, libelous, or otherwise unlawful or tortious material, including material harmful to children or violative of third party privacy rights; (iii) send or store material containing software viruses, worms, Trojan horses or other harmful computer code, files, scripts, agents or programs; (iv) interfere with or disrupt the integrity or performance of the Services or the data contained therein; or (v) attempt to gain unauthorized access to the Services or its related systems or networks.
3. Trial Period and Requirements to Convert to a full Subscription License
The Trial Period for the Trial Services will be for 30 days from the date Privacera software is downloaded (“Trial Download Date”), unless a) such trial period is for a longer term as specified by Privacera; or b) is extended by mutual Agreement of the parties. Customer acknowledges and agrees that, at the end of the Trial Period, Customer’s access to the Trial Services will be AUTOMATICALLY terminated, with or without notice, unless Customer elects to license the Services on a paid subscription basis. Customer must contact Privacera at least two (2) business days prior to the end of the Trial Period if Customer wishes to continue using the Services beyond the Trial Period. In the event Customer wishes to enter into a full production, subscription license for the use of the PRIVACERA SOLUTION, Customer will be required to (a) agree to a separate Master Customer Agreement through the Privacera website located at ____________________ (“Post Trial Agreement”), and (b) execute an Order Form, detailing the Services, duration and pricing applicable to the use of the Services.
4. Customer’s Responsibilities
Customer is responsible for all activity occurring under Customer’s designated User accounts and shall comply with all applicable laws and regulations in connection with Customer’s use of the Trial Services, including but not limited to those related to data privacy, international communications, the transmission of technical or personal data and export control laws and regulations. Customer shall: (i) notify Privacera immediately of any unauthorized use of any password or account or any other known or suspected breach of security with respect to the Services; (ii) report to Privacera immediately and use reasonable efforts to stop immediately any copying or distribution or misuse of Content, Privacera Technology, Services or Deliverable that becomes known or suspected by Customer or Customer’s Users; and (iii) not impersonate another Privacera user or provide false identity information to gain access to or use the Services. In performing its obligations under this Agreement, in the event that Customer processes credit cards using the Services, Customer acknowledges its responsibilities under the Payment Card Industry Data Security Standard (“PCI DSS”) and agrees to: a) implement and maintain reasonable security measures to protect cardholder data in its possession and b) not take any action when using the Services to place Privacera in non-compliance with PCI DSS (e.g. storing any cardholder data (even if encrypted) in any Services custom fields).Customer shall indemnify and hold Privacera, its licensors and each such party’s parent organizations, subsidiaries, affiliates, officers, directors, employees, attorneys and agents harmless from and against any and all claims, costs, damages, losses, liabilities and expenses (including attorneys’ fees and costs) to the extent arising out of or in connection with a claim alleging that use of the Customer Data infringes a copyright, patent, or a trademark of, or has caused harm to the rights of, a third party provided in any such case that Privacera (a) promptly gives notice of the claim to Customer; (b) gives Customer sole control of the defense and settlement of the claim (provided that Customer may not settle such claim unless such settlement unconditionally releases Privacera of all liability and does not adversely affect Privacera’s business or Service); (c) provides to Customer all available information and reasonable assistance; and (d) has not compromised or settled such third-party claim.
5. Customer Data
The Trial Services will be populated with Sample Data, and may allow for Customer to enter a limited amount of Customer Data. To the extent Customer enters any Customer Data into the Services, Customer, not Privacera, shall have sole responsibility for the accuracy, quality, integrity, legality, and intellectual property ownership or right to use all Customer Data, and Privacera shall not be responsible or liable for the deletion, correction, destruction, damage, or loss of such Customer Data. Privacera’s use of Customer Data shall be limited to the purpose of providing the Trial Services to the Customer. To the extent Customer enters Customer Data into the Services, Customer agrees and acknowledges that Privacera is not obligated to retain any Customer Data after termination or expiration of the Trial Period, and (ii) Privacera may delete Customer Data after the end of the Trial Period, without further obligation or liability to the Customer.
6. Intellectual Property Ownership
Privacera alone (and its licensors, where applicable) shall own all right, title and interest, including all related Intellectual Property Rights, in and to the Privacera Technology, the Content and the Services and Deliverables (if any), including to any and all enhancements, enhancement requests, suggestions, modifications, extensions and/or derivative works thereof. This Agreement is not a sale and does not convey to Customer any rights of ownership in or related to the Services, to any Deliverable, the Privacera Technology or the Intellectual Property Rights owned by Privacera. The Privacera name, the Privacera logo, and the product names associated with the Services are trademarks of Privacera or third parties, and no right or license is granted to use them.
7. Suspension and Termination
Privacera reserves the right to suspend or terminate this Agreement and the Trial Services, with or without cause, at any time, with or without notice. Customer may terminate the Trial Services, with or without cause, at any time, by providing a written notice to Privacera at [email protected]
8. Disclaimer of Warranty
THE SERVICES ARE PROVIDED “AS IS” AND PRIVACERA MAKES NO WARRANTIES OF ANY KIND, WHETHER EXPRESS, IMPLIED, STATUTORY OR OTHERWISE, AND PRIVACERA SPECIFICALLY DISCLAIMS ALL IMPLIED WARRANTIES, INCLUDING ANY WARRANTIES OF MERCHANTABILITY, NON-INFRINGEMENT AND FITNESS FOR A PARTICULAR PURPOSE OR ANY IMPLIED WARRANTIES ARISING OUT OF THE COURSE OF DEALING OR THE USAGE OF TRADE, TO THE MAXIMUM EXTENT PERMITTED BY APPLICABLE LAW. PRIVACERA DOES NOT WARRANT THAT THE SERVICES, (INCLUDING PROFESSIONAL SERVICES OR RELATED DELIVERABLES, IF ANY), ARE OR WILL BE ERROR-FREE, WILL MEET CUSTOMER’S REQUIREMENTS, OR BE TIMELY OR SECURE. CUSTOMER WILL NOT HAVE THE RIGHT TO MAKE OR PASS ON ANY REPRESENTATION OR WARRANTY ON BEHALF OF PRIVACERA TO ANY THIRD PARTY. PRIVACERA’S SERVICES MAY BE SUBJECT TO LIMITATIONS, DELAYS, AND OTHER PROBLEMS INHERENT IN THE USE OF THE INTERNET AND ELECTRONIC COMMUNICATIONS. PRIVACERA IS NOT RESPONSIBLE FOR DELAYS, DELIVERY FAILURES, OR OTHER DAMAGE RESULTING FROM SUCH PROBLEMS NOT CAUSED BY PRIVACERA.
9. Limitation of Liability
IN NO EVENT SHALL PRIVACERA’S AND ITS LICENSORS BE LIABLE FOR ANY DAMAGES, OF WHATEVER NATURE, AS A RESULT OF THIS AGREEMENT OR THE SERVICES, INCLUDING BUT NOT LIMITED TO ANY DIRECT, INDIRECT, PUNITIVE, SPECIAL, EXEMPLARY, INCIDENTAL, CONSEQUENTIAL OR OTHER DAMAGES OF ANY TYPE OR KIND (INCLUDING LOSS OF REVENUE, PROFITS, USE OR OTHER ECONOMIC ADVANTAGE) ARISING OUT OF, OR IN ANY WAY CONNECTED WITH THIS AGREEMENT OR USE OF THE SERVICES, INCLUDING BUT NOT LIMITED TO THE USE OR INABILITY TO USE THE SERVICES, OR FOR ANY CONTENT OBTAINED FROM OR THROUGH THE SERVICES, ANY INTERRUPTION, INACCURACY, ERROR OR OMISSION, REGARDLESS OF CAUSE, EVEN IF PRIVACERA OR PRIVACERA’S LICENSORS HAVE BEEN PREVIOUSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
10. Assignment
Customer may not assign this Agreement to any third party except upon Privacera’s prior written consent, which consent not to be unreasonably withheld. Any purported assignment in violation of this Section shall be void. This Agreement and each and all of the provisions hereof bind and benefit the parties and their respective heirs, executors, administrators, legal representatives, successors and assigns.
11. Confidentiality
Each party (as a “Receiving Party” hereunder) shall not disclose to any third party, any Confidential Information of the other party (as a “Disclosing Party” hereunder) provided to such Receiving Party in anticipation of, or in connection with the performance of this Agreement or the Post Trial Agreement. For the avoidance of doubt, this includes Confidential Information provided to the Receiving Party prior to the Effective Date of this Agreement. As used herein, the term “Confidential Information” refers to any and all financial, technical, commercial, or other information concerning the business and affairs of the Disclosing Party, including, without limitation, any cost or pricing information, contractual terms and conditions, marketing or distribution data, business methods or plans. If Confidential Information is (a) provided as information fixed in tangible form or in writing (e.g., paper, disk or electronic mail), such shall be conspicuously designated as “Confidential” (or with some other similar legend) or (b) provided orally, such shall be identified as confidential at the time of disclosure and confirmed in writing within thirty (30) days of disclosure, unless a reasonable person would understand such information to be confidential based on its content. Notwithstanding the above, Privacera Confidential Information shall include the Privacera Technology and all pricing terms offered to Customer under any Order Form, and Customer Confidential Information shall include Customer Data. Confidential Information does not include information which (i) becomes generally available to the public other than as a result of a disclosure by the Receiving party, (ii) was available to a party on a non-confidential basis prior to its disclosure by the other party or in connection with the performance by such party of its obligations under this Agreement, or (iii) becomes lawfully available to a party on a non-confidential basis from an independent third party. The Receiving Party will not use Confidential Information for any purpose other than carrying out its obligations as set forth in this Agreement or, if applicable, the Post Trial Agreement, and shall not disclose Confidential Information to any third party, without the prior written consent of the Disclosing Party and an agreement in writing from the third party that it will adhere to the confidentiality obligations imposed herein. Third parties shall not include agents of the Receiving Party, employees or affiliates of the Receiving Party, attorneys, accountants, and other professional advisors of the Receiving Party, in each case such person must have a legitimate reason to have access to such Confidential Information and must be under a duty to protect such Confidential information which duty is substantially equivalent to the obligations contained herein. Each Receiving Party’s confidentiality obligations with respect to such Confidential Information, shall remain in effect for the term of this Agreement and Post Trial Agreement and for a period of three (3) years after the termination or expiration of this Agreement and, if applicable, the Post Trial Agreement.
12. General/Notices
This Agreement shall be governed by California law and controlling United States federal law, without regard to the choice or conflicts of law provisions of any jurisdiction, and any disputes, actions, claims or causes of action arising out of or in connection with this Agreement or the Trial Services shall be subject to the exclusive jurisdiction of the state and federal courts located in Santa Clara, California. If any provision of this Agreement is held by a court of competent jurisdiction to be invalid or unenforceable, then such provision(s) shall be construed, as nearly as possible, to reflect the intentions of the invalid or unenforceable provision(s), with all other provisions remaining in full force and effect. No joint venture, partnership, employment, or agency relationship exists between Customer and Privacera as a result of this Agreement or use of the Trial Services. The failure of either party to enforce any right or provision in this Agreement shall not constitute a waiver of such right or provision unless acknowledged and agreed to by such party in writing. This Agreement, (including any other documents referenced therein), comprises the entire agreement between Customer and Privacera regarding the subject matter contained herein and supersedes all prior or contemporaneous negotiations, discussions or agreements, whether written or oral, between the parties regarding such subject matter. All notices from Customer to Privacera may be made by emailing [email protected] and Privacera may give notice by emailing Customer’s contact as specified on the registration form. Customer agrees that “Powered by Privacera” or similar marks may appear in forms, web pages and other outputs of the Trial Services.
13. Definitions
As used in this Agreement and/or in any Trial Service materials associated herewith:
“Content” means the audio and visual information, documents, software, products and services contained in or made available via the Trial Services, other than Customer Data; “Customer Data” means any data, information or material that Customer or Customer’s Users, subscribers or partners may disclose or submit to Privacera or the Trial Services in the course of using the Trial Services; “Sample Data” means any pre-populated data provided in the Trial Services to enable Customer to use the Trial Services without entering its own Customer Data; “Intellectual Property Rights” means unpatented inventions, patent applications, patents, design rights, copyrights, trademarks, service marks, trade names, domain name rights, mask work rights, know-how and other trade secret rights, and all other intellectual property rights, derivatives thereof, and forms of protection of a similar nature anywhere in the world; “Order Form(s)” means the form evidencing the initial subscription order for the Services and any subsequent Order Forms submitted online or in written form, specifying, among other things, the Services contracted for, the applicable Fees, the billing period, and other charges as agreed to between the parties; “Privacera Technology” means all of Privacera’s proprietary technology (including Sample Data, software, hardware, products, processes, algorithms, user interfaces, know-how, techniques, designs and other tangible or intangible technical material or information) made available to Customer by Privacera in providing the Trial Services; “Service(s)” means Privacera’s online integrated subscription management, billing, data analysis, or other Z-Billing services to which Customer is being granted access to on a trial basis under this Agreement, including the Privacera Technology, the Content and any product, service or license belonging to a any third party that is part of the Trial Services; “User(s)” means Customer’s employees, representatives, consultants, contractors or agents who are authorized to use the Trial Services and have been supplied temporary user identifications and passwords by Customer (or by Privacera at Customer’s request); “Trial Services” means access to a designated sub-set of Services and functionality for the purpose of enabling Customer to evaluate the Services during the Trial Period; “Trial Period” means the duration of the Trial Period, starting on the Trial Service Activation Date, and ending at the end of thirty (30) days or such other period as mutually agreed by the parties; “Deliverables” means any copyrightable works, products, discoveries, developments, designs, work product, deliverables, improvements, inventions, processes, techniques and know-how made, conceived, reduced to practice or learned by Privacera (either alone or jointly with Customer or others) that result from professional services (if any) provided in connection with the Trial Services.