PUBLIC BETA COMING SOON…
Contact us at [email protected] for inquiries
Contact us at [email protected] for inquiries

Ingest · Prepare · ETL · Feature Generation · Model Training · Model Deployment


UNIFIED ANALYTICS DESIGN LAYER



From File or Databases
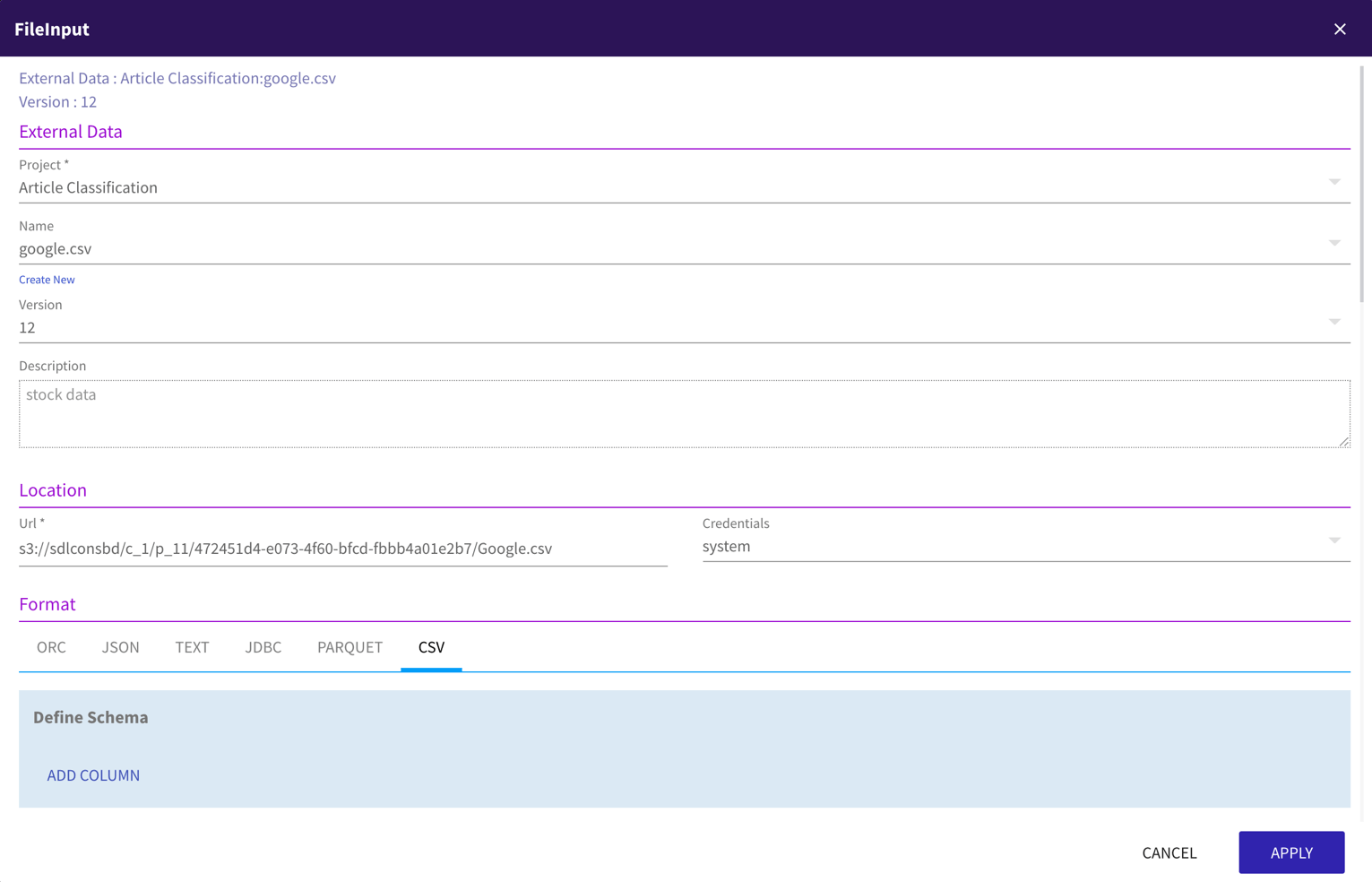
Data Ingestion allows data to be ingested from a file in cloud storage such as S3 – various file formats are supported.
You can also get the data from a database using the JDBC connector.
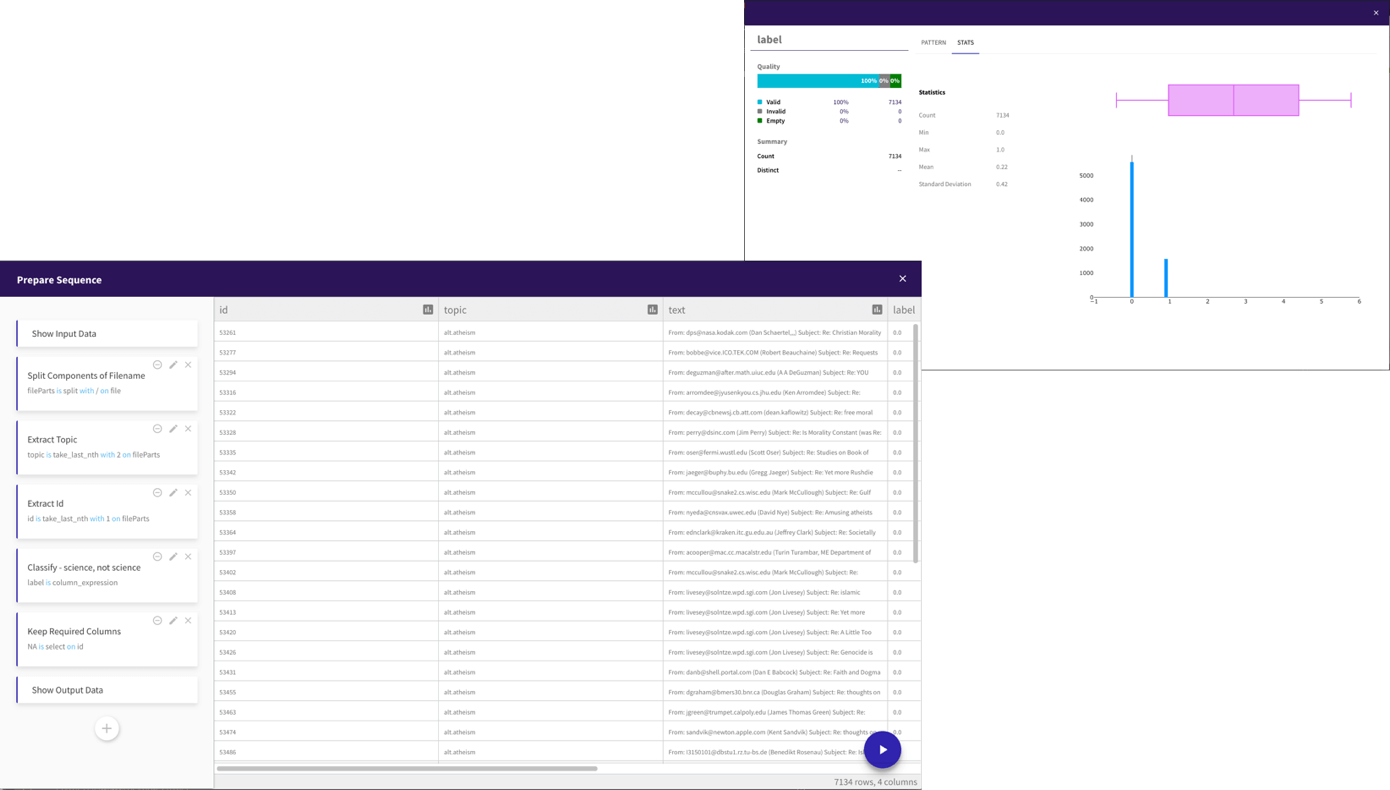
Use spreadsheet view to understand your data and statistics about its quality and distribution Use prepare functions to modify data, with over 200 built-in functions and any SQL expression can be written
Use SQL Queries and SQL operators to combine and transform data into the shape you want.
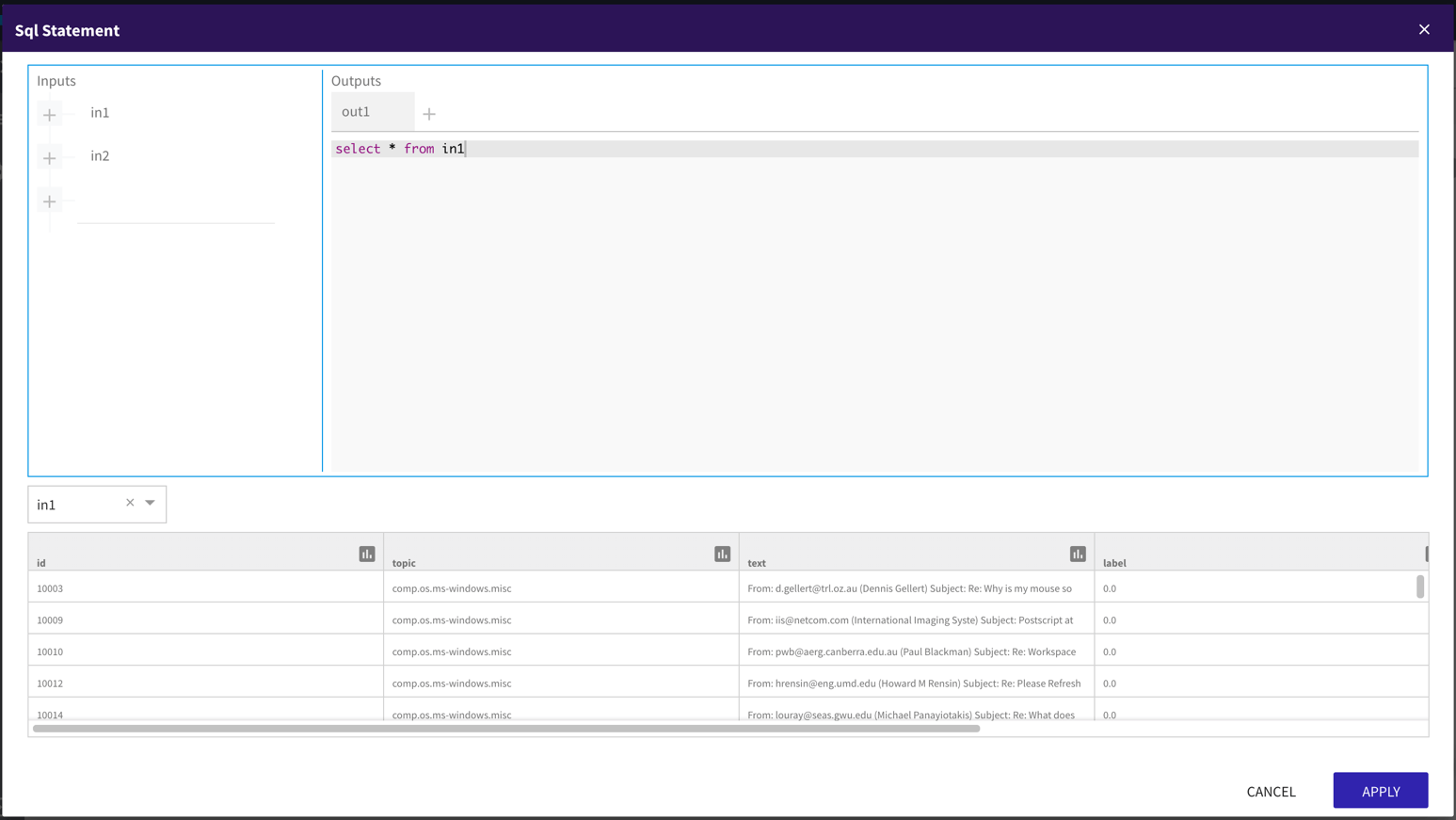
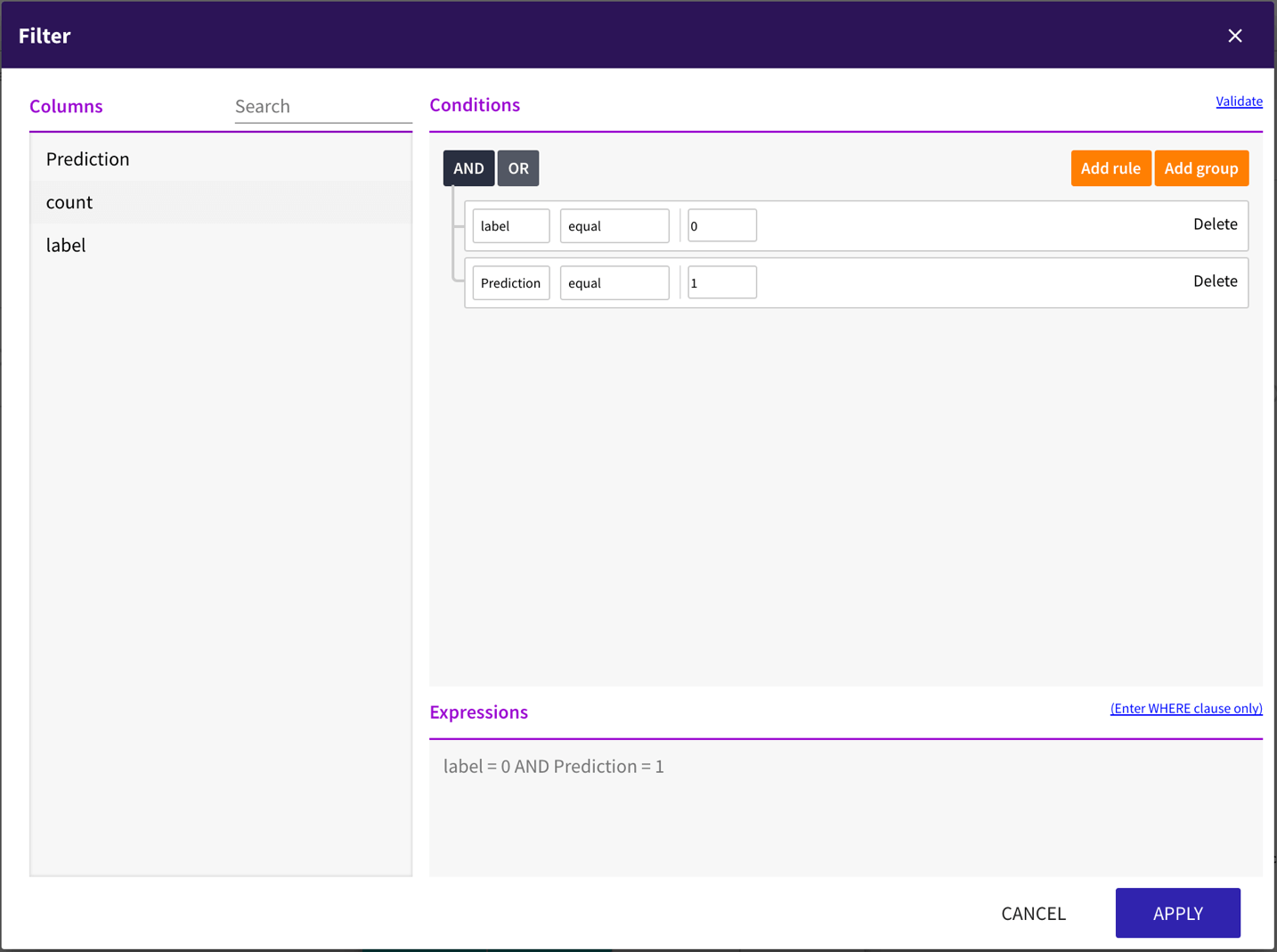
We support complete SparkSQL and SQL 2003.
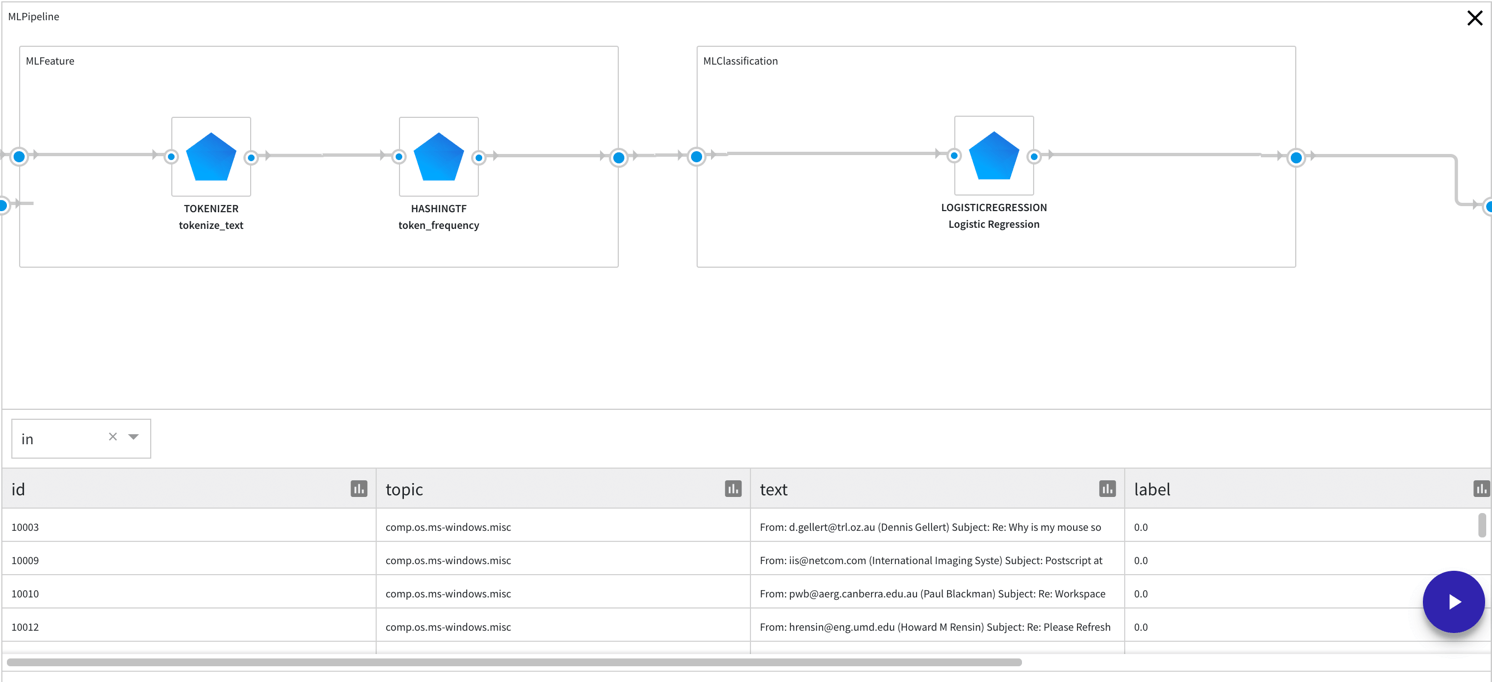
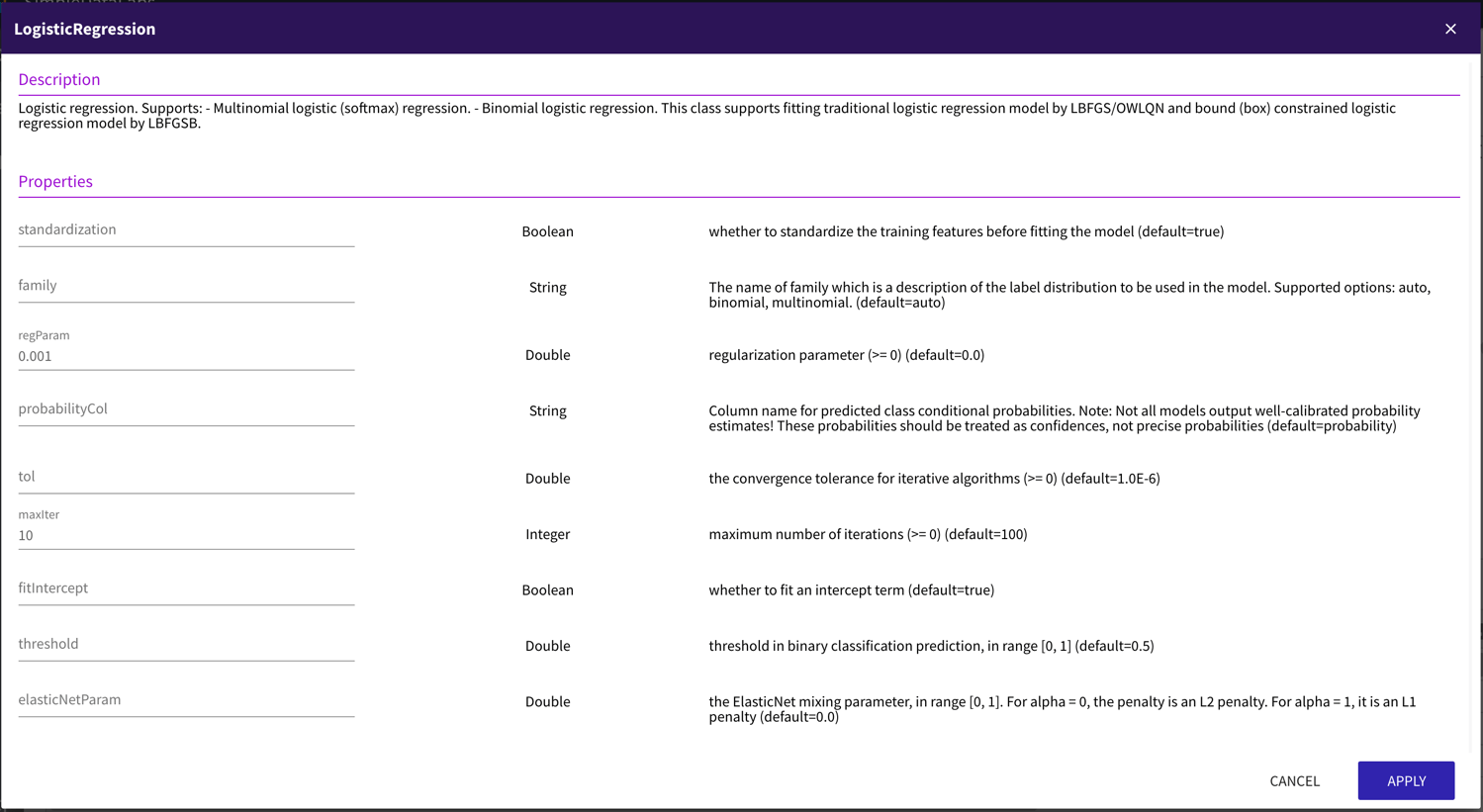
ML Pipeline builder allows you to build simple pipelines or pipelines with hyper-parameter tuning.
See the features you are generating immediately including statistics on the created columns
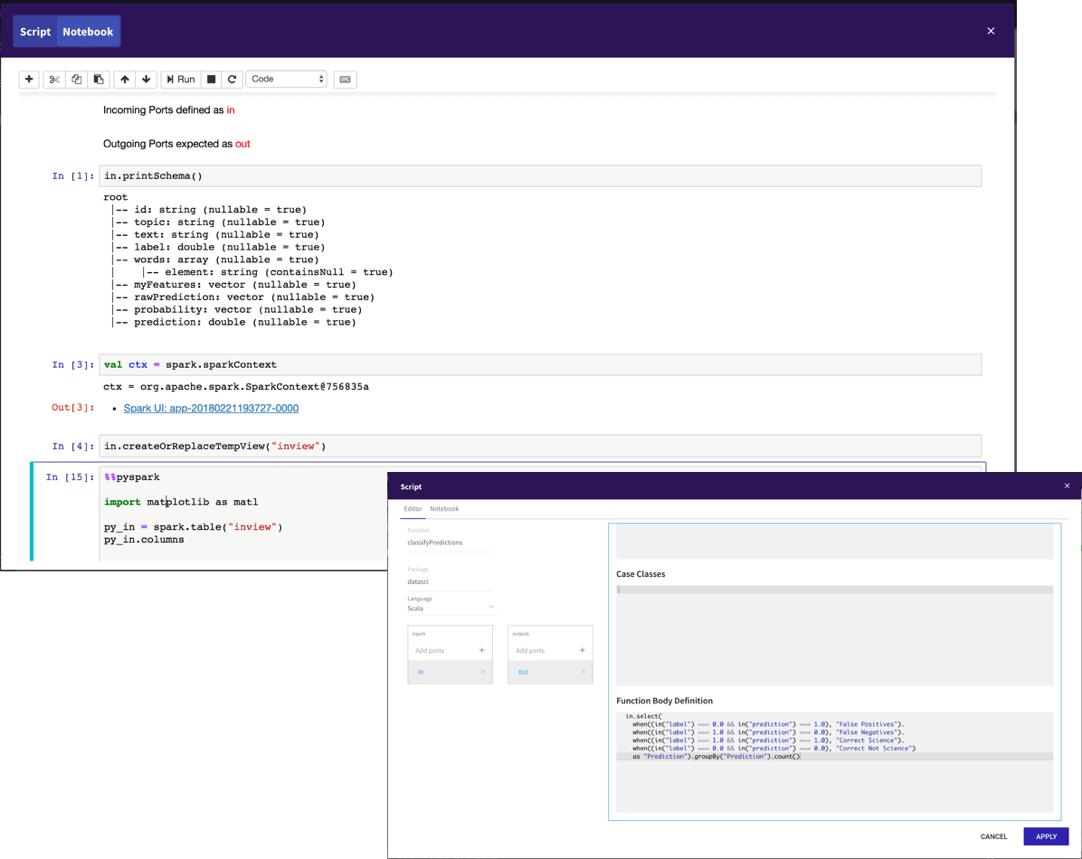
Script Node comes with an inbuilt Jupyter notebook connected to the same Spark as the workflow.
Use the notebook to experiment and generate a function.
Use the final function as a script in your workflow. Scripts can be saved and reused
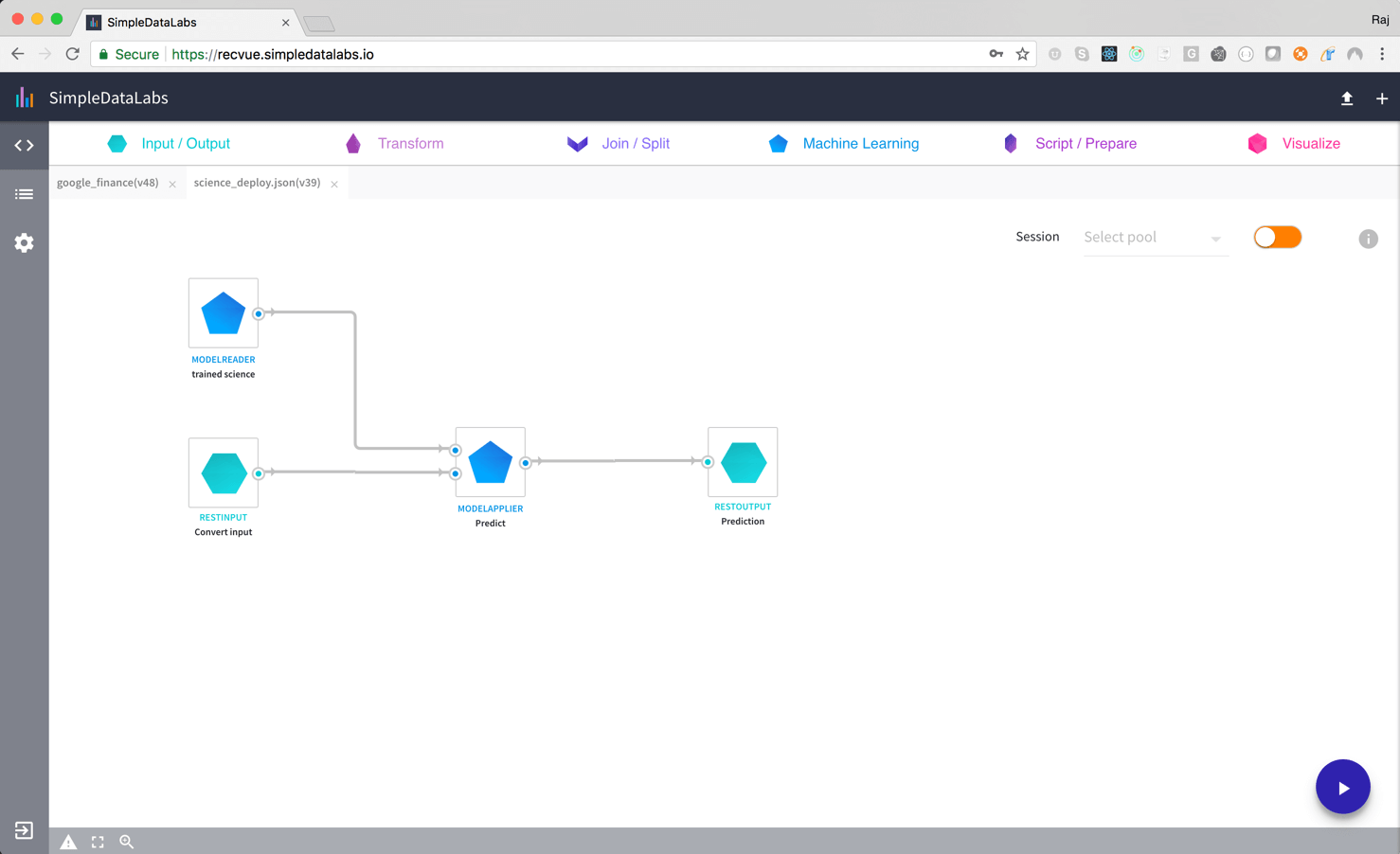
Powerful and flexible deployment as model, web service or pod. Versioning and monitoring makes it reliable. High performance with low latency and high concurrency.
From File or Databases
Data Ingestion allows data to be ingested from a file in cloud storage such as S3 – various file formats are supported.
You can also get the data from a database using the JDBC connector.
Use spreadsheet view to understand your data and statistics about its quality and distribution Use prepare functions to modify data, with over 200 built-in functions and any SQL expression can be written
Use SQL Queries and SQL operators to combine and transform data into the shape you want.
We support complete SparkSQL and SQL 2003.
ML Pipeline builder allows you to build simple pipelines or pipelines with hyper-parameter tuning.
See the features you are generating immediately including statistics on the created columns
Script Node comes with an inbuilt Jupyter notebook connected to the same Spark as the workflow.
Use the notebook to experiment and generate a function.
Use the final function as a script in your workflow. Scripts can be saved and reused
Powerful and flexible deployment as model, web service or pod. Versioning and monitoring makes it reliable. High performance with low latency and high concurrency.
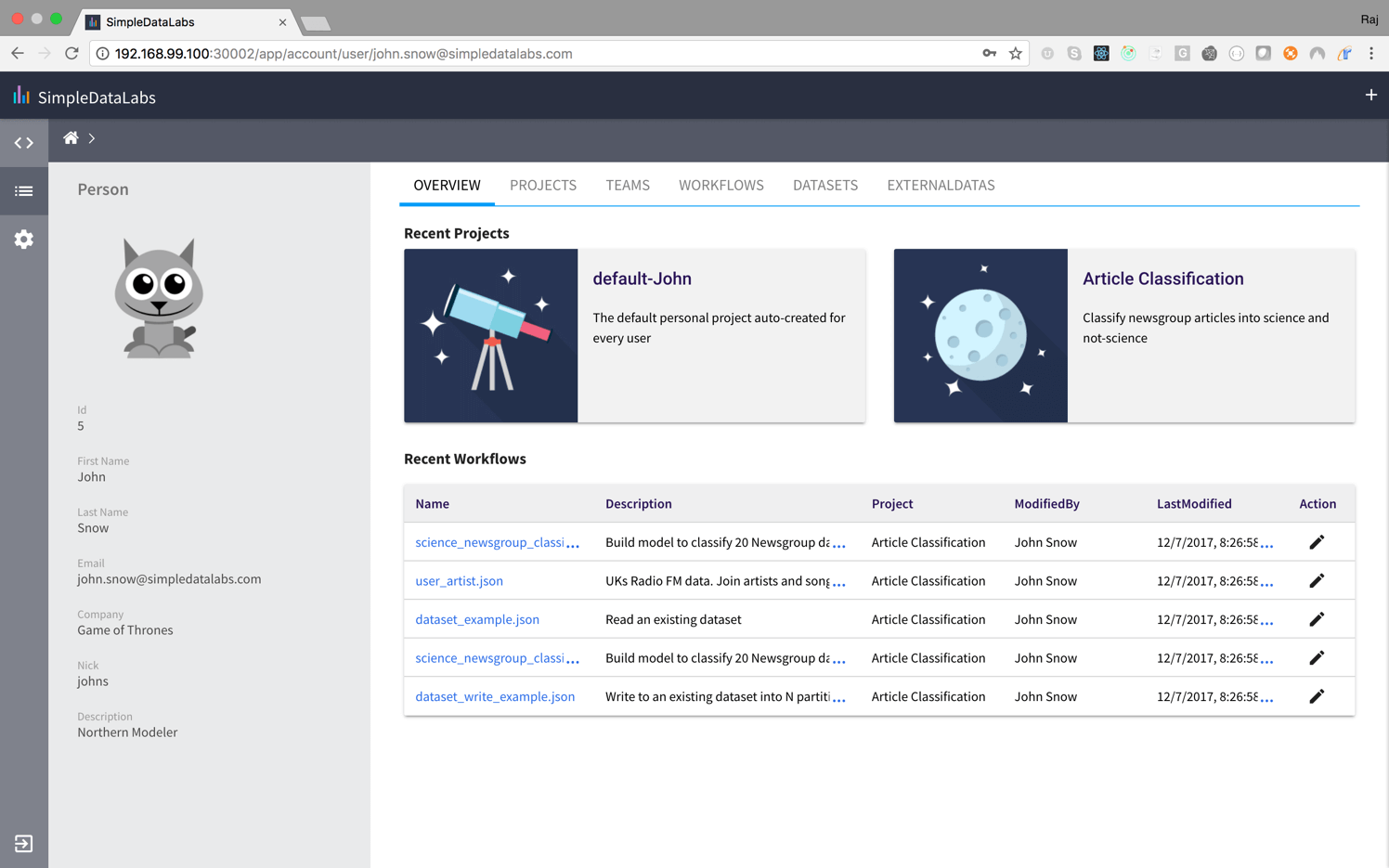
The Catalog allows teams to collaborate on shared projects where you can share datasets, workflows and even scripts.
Versioning ensures that no information is lost on multiple updates when collaborating
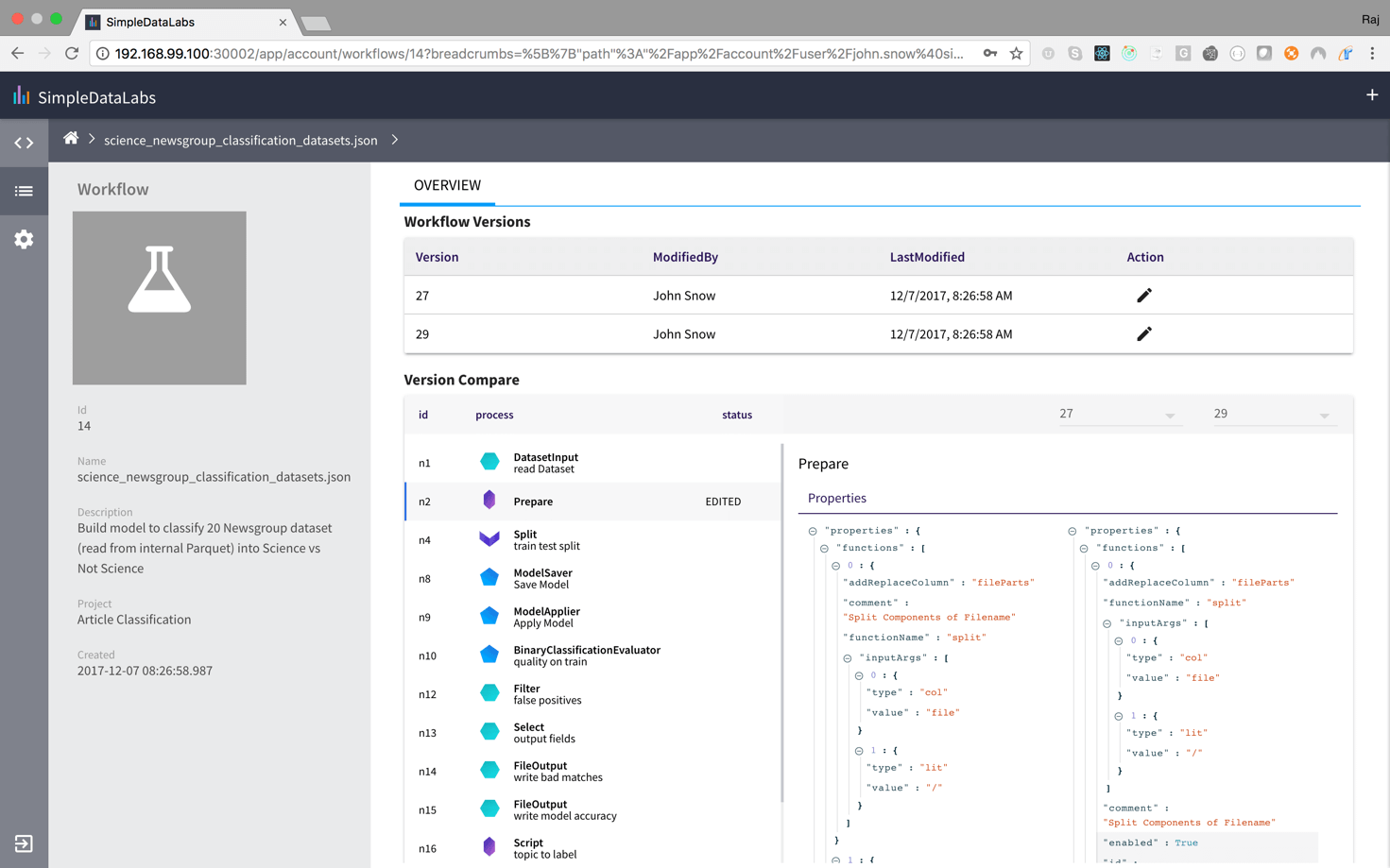

Build Workflows
Interactive Development with incremental execution to build workflows on Spark

Execute and Schedule
Execute and Schedule workflows to runon Spark with requested resources - your workflow will run at 100GB or 10TB

Get Production Support
With us, you get a good night’s sleep. We’ll take care of any execution issues and help support SLAs that you want to deliver.
SQL
Recommendation
Classification
Clustering
Regression
Feature Generation

Write your own custom operators in 100% Apache Spark that are unique to your business. Avoid lock-in into a custom framework.